Looked at some of the results from Nsights performance analysis tools for CUDA and looked at how they could be used within the project to give an insight into how well the application is performing in terms of branching and memory usage.
Also decided to look at a parallel implementation of Dijkstra as well, having a quick look around Google there appear to be lots of example implementations where people have attempted to parallelize the algorithm.
Aim for this week is to read over some of the existing work that has been done using parallel Dijkstra implementations.
Tuesday, 10 December 2013
Monday, 2 December 2013
Meetings: Friday 29th November
Discussed the list of tests that were outlined in the testing plan and went over what measurements should be recorded from the tests.
Not a lot of work has been completed on the project over the last week due to upcoming coursework and exams.
Not a lot of work has been completed on the project over the last week due to upcoming coursework and exams.
Thursday, 28 November 2013
Testing Plan
Minimum Tests For Project To Be Succesful
- Time sequential diffusion application
- Time parallel diffusion application
- Compare paths of sequential and parallel diffusion in terms of distance, correctness and quality
- Time sequential Dijkstra
- Compare paths from diffusion and dijkstra in terms of distance, correctness and quality.
Extra Tests If Time Allows
- Look at number of agents against time to find a path
- Look at how paths handle introduction of obstacles over time
- Introduce obstacles which are static once placed
- Introduce dynamic obstacles
- Look at moving goals.
Saturday, 23 November 2013
Meetings: Friday 22nd November 2013
Discussed the technical work that has been done so far and went over the initial timings that were taken for both the sequential and parallel versions of the diffusion application.
Agreed that due to the nature of the diffusion pathfinding it would be unfair to compare to A* as the diffusion process returns all paths to a goal node whereas A* only returns a single path. Due to this it may be better to compare against an implementation of Dijkstra instead.
Need to come up with a plan of tests which need to be run that includes a range of challenges for the algorithm to deal with such as static and dynamically changing goals etc.
Wednesday, 20 November 2013
Technical Work: Parallel vs Sequential Diffusion
This week i have been working on a simple parallel implementation of the diffusion process. In this post i am going to explain and compare the code from both the sequential and parallel implementations and look at some initial timing results.
For a background on the diffusion process that has been implemented please see this post on collaborative diffusion.
I am also assuming the user has some prior knowledge of parallel programming or CUDA development. An excellent book on the subject that i would recommend reading is CUDA by example by Jason Sanders and Edward Kandrot








In this example after 10 iterations we can now find a path from anywhere in our grid, although the number of iterations needed to fill the grid depends on the size of the grid.
In the image below the red squares represent agents placed around our grid, by moving to the neighbouring tile with the highest diffusion value we can find a path back to our goal tile from any position in the grid.








For a background on the diffusion process that has been implemented please see this post on collaborative diffusion.
I am also assuming the user has some prior knowledge of parallel programming or CUDA development. An excellent book on the subject that i would recommend reading is CUDA by example by Jason Sanders and Edward Kandrot
Sequential Implementation
Before we can start calculating our diffusion values in order to find paths from our agents to our goals we first need to some way to store our values. For this we use three, 2 dimensional vectors. One to store our input grid, one for the output grid and one that contains the goals we will be seeking. Optionally we can also have a fourth grid that contains walls and obstacles.

Once we have our grids set up with the values all initialised to zero and our goal tile set to an arbitrarily high value, (in our case the centre tile is set to 1024) we can then begin the diffusion process.
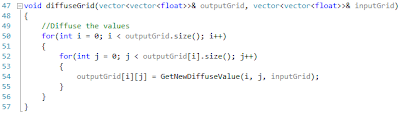
This process follows three simple steps; First we copy our goal values into the input grid (line 128), we then diffuse the 'scent' of our goal value across our grid storing our newly calculated values in the output grid (line 131) and finally we swap our input and output grids ready for the next iteration.

Setting our goals is a very simple process, all we need to do is loop through our goal grid and find which values do not equal zero and set the corresponding tile in the input grid to our goal value.

Our diffusion process is a little more involved and is the most computationally heavy process we have. In order to diffuse the grid we need to loop through every tile in the grid and calculate its new value. This is done by taking the value of the left, right, top and bottom neighbours and computing the average of the tiles (Line 42) and storing the new value in the output grid.

Finally we swap the input and output grids ready for the next iteration using the swap() method provided by the C++ library.
And there we are, we have run one iteration of our diffusion process! If we print the values from our output grid to a .csv file we get something that looks like this.

As we can see our values are starting to diffuse out from our goal tile and spread across the grid but after one iteration we still cant find a path to our goal unless we are standing right next to it so we need to run our diffusion process a few more times.

Starting to get there....just few more times.

In this example after 10 iterations we can now find a path from anywhere in our grid, although the number of iterations needed to fill the grid depends on the size of the grid.
In the image below the red squares represent agents placed around our grid, by moving to the neighbouring tile with the highest diffusion value we can find a path back to our goal tile from any position in the grid.

One of the benefits of being able to find a path from anywhere in the grid is that if our goals are static we only need to calculate the values once and we can store them in a look up table for our agents to use.
Parallel Implementation
Our parallel implementation mostly follows the same process as our sequential version, the only real differences are we now need to change the code so that it can be run on the GPU. To do this we are going to use CUDA C/C++.
Like before the first thing we need to do is create variables for holding our three grids and allocate the memory for them on the GPU.


Once we have this we then create a temporary variable on the CPU which we use to initialise all the values in the grid to zero and set our initial goal values. Again we use the centre tile in the grid and set the value to 1024. We then copy our temporary variable from our CPU into our three variables stored on the device.

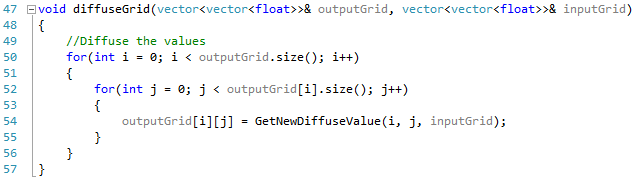
After all our memory is set up on the GPU we can now call our kernels to run our diffusion process. Like the sequential version we follow the same three steps as before. First we copy our goals into our input grid (Line 119). Secondly we calculate our new diffusion values (Line 122) and finally we swap our input and output grids ready for the next iteration (Line 125).

Our copy_const_kernel follows the same idea as setting our goals did in the sequential version. However this is where the power of parallelization begins to come in as we now no longer need to loop through our entire grid, instead we simply find which tile in the grid the thread is working on and check to see if that tile contains a goal value. If it does we set the goal at this position in the input grid.

The diffuse_kernel again works in a very similar way, we find the tile we are working on and then get the diffusion values for the left, right, top and bottom neighbours before computing an average and setting this to the value of the corresponding tile in the output grid.

Finally we swap our input and output grids using the swap() method from the C++ library like we did before.
The final step we need to take into consideration when programming for the GPU is getting our values back onto the CPU once we are finished processing. After we have run our diffusion process for our desired number of iterations we can now pass our data back and store it again in our temporary variable and use it in anyway we wish.
Time Differences
Overall there is not much difference from our sequential version in terms of the process that we follow and even the amount of code that we have to write. The biggest difference between the applications only becomes noticeable when we start to measure the performance.
For each of the applications we have measured the time taken to run one iteration of the diffusion process, this involves copying our goals into the input grid, calculating the new values and swapping the input and output grids. This process has been run 100 times and an average time has been taken.
The applications have been run on grids of 32x32, 64x64, 128x128, 256x256, 512x512, 1024x1024 and 2048x2048.

Looking at the timings for the different grid size of the sequential version we can see that as the grid size increases so does the time taken to process all the nodes, starting at 0.73ms for a 32x32 grid and moving up to 3 seconds for a grid size of 2048x2048.
Initially this doesn't seem to bad at first glance but we need to remember that we cant find paths from everywhere in our grid until the 'scent' of our goal has spread to every tile. Based upon testing with the parallel implementation it takes at least 40,000 iterations to fill the entire grid so that every tile has a non zero value for a grid of size 2048x2048, This would mean it would take at least 33 hours before we could find all our paths! Ain't nobody got time for that!

Looking at our parallel times we can see that it follows the same trend as before with our larger grids taking more time to process. However when we look at our actual times we can see a massive difference in speed compared to our sequential versions.
For our parallel implementation it only takes us 2.44 ms to run our diffusion process for the 2048x2048 grid compared to the 3000 ms of the sequential version. This is also faster than the sequential version for the 64x64 grid even though the 2048x2048 grid is 32 times larger in size!
This also means that we are able to find all paths to our goal a lot quicker in parallel for our 2048x2048 grid. Considering that it takes at least 40,000 iterations so that all tiles have a non zero value it would only take 97 seconds to find all paths in parallel compared to 33 hours if we done it sequentially. Although still not quite real time it is a lot better!
Friday, 8 November 2013
Meetings: Week 9 Review
Had the week 9 review with the second marker. Discussed the lit review and aims of the project and received feedback on the project.
Feedback
- Changes heading on lit review section Artificial intelligence in games to pathfinding algorithms in games.
- Add a section on dijkstra's algorithm.
- Test cases need to be well designed, Take as many timings as possible and get an average and use t testing to determine if the data sets are significantly different from one another.
Overall the feedback was positive and constructive, the project is on track and has clear goals about what needs to be achieved for the project to be successful.
Thursday, 7 November 2013
Technical Work: Sequential Diffusion
Implemented a simple application in which agents seek out food items within a maze using the collaborative diffusion algorithm to find the quickest path to the nearest item. The yellow cubes represent the agents, green spheres are food objects and orange cubes are walls which are impassable.
Collaborative Diffusion Explanation
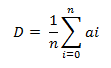




By its very nature collaborative diffusion lends
itself very well to a data parallel implementation on the GPU, as the GPU works
by splitting the work across a number of threads and having each thread perform
the same task it should be more than possible to split the work of the tiles
across a number of threads as each tile performs the same diffusion
calculation.
Collaborative Diffusion Explanation
Traditionally
in a game each agent will have its own pathfinding routine that will be called
any time an agent needs to find a path to a specific goal state. Typically in
the majority of games this will call the A* algorithm, this works well in most
cases but as the number of agents increases the time spent pathfinding also
increases which can have a detrimental effect on the performance of the game.
To combat
this collaborative diffusions works on the idea of antiobjects, an antiobject
is a type of object that appears to do the opposite of what we would generally
think the object would be doing (Repenning, 2006) .
For example in the game Pac man (Pac-Man, 1980) the objective of each ghost is to find
Pac man. Using traditional pathfinding like A*, each ghost would run its own
pathfinding algorithm every time it needed a new path. From an object
orientation stand point this makes sense to many programmers that the
responsibility of finding a path would be down to each agent, however by
removing the computation from the objects that typically appear to do the
search, it allows the computation to be redistributed in a parallel fashion to
the objects that define the space to be searched instead.
Diffusion is a gradual
process in which physical and conceptual matter, such as molecules, heat,
light, gas, sound and ideas are spread over an N-dimensional physical or
conceptual space over time (Repenning, 2006) , within collaborative diffusion this
idea is used to transfer the scent of a goal state throughout the world in
which pathfinding will be taking place. This diffusion value is calculated
using the following equation.
Where:
D = diffusion value
n = number of neighbours
a = diffusion value of
neighbour.
Typically
the world is organised as a grid representing either a 2D or 3D environment and
each neighbour is defined according to the Moore neighbourhood (Moore Neighbourhood, 2013) which comprises of
the eight cells surrounding a central cell.
Each goal
state is given an initially high diffusion value which is used as the starting
state as shown by the green tile in Figure 2 below.

Figure 2 - starting state
During the
first iteration the diffusion value for all the tiles are calculated using the
diffusion equation. After this iteration the tiles surrounding the goal state
now have a larger diffusion value than they had initially and the ‘scent’ of
the goal state is beginning to move toward the agent as shown in Figure 3 below.

Figure 3 - Iteration one
This process
continues again for all of the tiles in the world during the next iteration, as
the diffusion value is calculated again for all the tiles it begins to spread
out further from the goal state expanding the ‘scent’ of the goal further
across the grid and towards the agent. During this iteration the diffusion
value of the tiles surrounding the goal state becomes larger making the goal
state appear more attractive to an agent. This second iteration is shown in Figure 4 below.

Figure 4 - Iteration two
At each
iteration the diffusion process repeats expanding further and further outwards
across the tiles. Eventually the ‘scent’ produced by the tiles will reach an
agent at which point a path can be found to the goal state.

Once the
‘scent’ has reached the agent, it is possible for a path to the goal state to
be found, unlike pathfinding algorithms like A* which use a back tracking
algorithm to find a path from the starting state to the goal state all the
agent simply has to do is look up the diffusion values of the tiles
neighbouring the tile it is currently on and move to whichever one has the
highest diffusion value.
As shown in Figure 5 during the third iteration our agent
is able to pick up the ‘scent’ of the goal state, by simply moving to the
neighbour with the highest diffusion value our agent is able to find the
quickest path to the goal as represented by the green tiles.
Collaborative
diffusion allows agents to collaborate together to complete objectives in a
very simple manner. In his paper collaborative diffusion: programming
antiobjects, Alexander Repenning states that there are four different types of
agents that allow collaboration to occur:
- 1 Goal Agents: Goal agents are pursued by other agents and can be either static or mobile.
- 2 Pursuer Agents: A pursuer agents is an agent that is interested in one or more of the goal agents. Multiple pursuer agents may be interested in the same goal and may collaborate or compete with one another.
- 3 Path Environment Agents: A path environment agent allows pursuer agents to move towards a goal agent and participates computationally in the diffusion process. In a simple arcade game this could be a floor tile in a maze.
- 4 Obstacle Environment Agents: Work in a similar manner to path environment agents but rather than helping an agent to reach the goal they interfere with the agents attempt to reach a goal. This could be represented by a wall or obstacle in a room.
Making use
of these different types of agents Repenning noticed that agents would appear
to collaborate with one another to reach a goal. He also states that the
collaboration between the agents is an emergent behaviour as no code is
explicitly responsible for orchestrating a group of agents but is instead a
result of the diffusion process and the way in which pursuer agents find a path
to goal agents through the path environment agents. Another interesting
observation by Repenning is that as the number of agents is increased the time
taken to perform the pathfinding remains constant (Repenning, 2006) .
Bibliography
Pac-Man.
(1980). Retrieved October 26, 2013, from Pac-Man:
http://pacman.com/en/pac-man-history/
Repenning, A. (2006). Collaborative Diffusion:
Programming Antiobjects. Boulder: University of Colorado.
Friday, 1 November 2013
Meetings: Friday 1st November 2013
Not much work was done on the background for the project this week due to other coursework deadlines.
Went over techniques that could help with the flow of the document as it is felt that this could be better. This includes writing everything up and then going back at the end and adding in a couple sentences to each section to help with the flow. It may also be helpful to create a flow diagram for each section and follow this.
Also discussed the existing work chapter, rather than having a heading for each paper instead talk about the main points of the paper and use the paper as a reference. For example talk about parallel AI and some of the considerations that need to be taking into account as referenced in the paper by Timothy Johnson and John Rankin and then talk about a* pathfinding and reference the paper by Owen Mcnally. Rather than talking about the paper on collaborative diffusion in this section, discuss it in the section on diffusion.
The week 9 meeting is scheduled to be for Friday the 8th if the second marker is available. For this the draft of the background is to be sent to the second marker the day before and a 1 to 2 page report on the technical work needs to be written up.
Went over techniques that could help with the flow of the document as it is felt that this could be better. This includes writing everything up and then going back at the end and adding in a couple sentences to each section to help with the flow. It may also be helpful to create a flow diagram for each section and follow this.
Also discussed the existing work chapter, rather than having a heading for each paper instead talk about the main points of the paper and use the paper as a reference. For example talk about parallel AI and some of the considerations that need to be taking into account as referenced in the paper by Timothy Johnson and John Rankin and then talk about a* pathfinding and reference the paper by Owen Mcnally. Rather than talking about the paper on collaborative diffusion in this section, discuss it in the section on diffusion.
The week 9 meeting is scheduled to be for Friday the 8th if the second marker is available. For this the draft of the background is to be sent to the second marker the day before and a 1 to 2 page report on the technical work needs to be written up.
Friday, 25 October 2013
Meetings: Friday 25th October 2013
Went over the current draft of the background. Agreed that this should be completed by Friday 1st of November to be sent to second marker in time for the week 9 review.
For the week 9 review need to complete a report on what other work has been carried out during the project, including any practical work or other research, also need to create a revised plan of what work is to be done and estimated dates of when this will be completed.
Received feedback from IPO. Main feedback was that the project could be too complex a project for honours level, it is important to establish where this project is re-implementing existing algorithms or develops new ones.
For the week 9 review need to complete a report on what other work has been carried out during the project, including any practical work or other research, also need to create a revised plan of what work is to be done and estimated dates of when this will be completed.
Received feedback from IPO. Main feedback was that the project could be too complex a project for honours level, it is important to establish where this project is re-implementing existing algorithms or develops new ones.
Friday, 18 October 2013
Meetings: Friday 18th October 2013
Went over the work that has been done on the lit review, agreed that it is along the right tracks and to continue with it, with the aim to be completed by week 9 review. Agreed that more detail is needed on the working of the GPU as this will be specific to the implementation.
Found an A* CPU implementation that has been used in professional triple A games. This will be modified to suit the needs of the project and used as a benchmark to compare the GPU implementation of a diffusion based algorithm.
Asked to get a copy of the work on pathfinding from the computational intelligence module as this may be helpful.
Still wait on feedback from IPO from second marker.
Found an A* CPU implementation that has been used in professional triple A games. This will be modified to suit the needs of the project and used as a benchmark to compare the GPU implementation of a diffusion based algorithm.
Asked to get a copy of the work on pathfinding from the computational intelligence module as this may be helpful.
Still wait on feedback from IPO from second marker.
Friday, 11 October 2013
Meetings: Friday 11th October 2013
Presented a draft of the sections that are to be included in the lit review. Agreed that don't need to go into too much detail about the different types of parallel systems only need to give a brief overview.
Look more closely at why using the GPU and why the particular technology could be useful for running pathfinding algorithms. highlight the differences and the advantages/disadvantages over the CPU.
Look at the different APIs that are available for programming on the GPU and give a justification about the chosen API.
Look at the different types of pathfinding algorithms which are available and what is traditionally used in games.
Highlight the advantages/disadvantages in the context of the project and look at the existing work that has been done and pick out what the findings/conclusions are and how they relate to the current project.
Discussed how the algorithms are going to be compared and what the best method of comparing the algorithms would be. Decided that A* is going to be very difficult to paralyze and that the best method if running a GPU implementation of A* would be to test it for a large number of agents and look at the scalabilty in comparison to the GPU. This has already been a few times in the past so it may be better to compare a CPU implementation of A* for a large number of agents against a GPU implementation of a diffusion based algorithm and see which has the better scalabilty and performance. The reason for this is that a CPU A* implementation is what is traditionally used in games so by comparing it against a different algorithm implemented on the GPU it may be possible to find a better algorithm for performing pathfinding within games?
Discussed how rendering could be effected by running the algorithms on the gpu for a large number of agents. Concluded that rendering is not important as the problems are the same for the CPU and GPU implementation, at this stage is has been decided that no rendering of agents will be carried out however if the project is successful and there is time left over it is something that could be implemented to make the application more visually appealing.
Aims for the coming week are to complete a first draft of the lit review in preparation for the week 9 meeting.
Look more closely at why using the GPU and why the particular technology could be useful for running pathfinding algorithms. highlight the differences and the advantages/disadvantages over the CPU.
Look at the different APIs that are available for programming on the GPU and give a justification about the chosen API.
Look at the different types of pathfinding algorithms which are available and what is traditionally used in games.
Highlight the advantages/disadvantages in the context of the project and look at the existing work that has been done and pick out what the findings/conclusions are and how they relate to the current project.
Discussed how the algorithms are going to be compared and what the best method of comparing the algorithms would be. Decided that A* is going to be very difficult to paralyze and that the best method if running a GPU implementation of A* would be to test it for a large number of agents and look at the scalabilty in comparison to the GPU. This has already been a few times in the past so it may be better to compare a CPU implementation of A* for a large number of agents against a GPU implementation of a diffusion based algorithm and see which has the better scalabilty and performance. The reason for this is that a CPU A* implementation is what is traditionally used in games so by comparing it against a different algorithm implemented on the GPU it may be possible to find a better algorithm for performing pathfinding within games?
Discussed how rendering could be effected by running the algorithms on the gpu for a large number of agents. Concluded that rendering is not important as the problems are the same for the CPU and GPU implementation, at this stage is has been decided that no rendering of agents will be carried out however if the project is successful and there is time left over it is something that could be implemented to make the application more visually appealing.
Aims for the coming week are to complete a first draft of the lit review in preparation for the week 9 meeting.
Friday, 4 October 2013
Meetings: Friday 4th October 2013
Went over Gantt chart and reviewed dates and times for each section. Agreed that the write up should be a continual process throughout the entire project and not just at the end of the project. Gantt chart will be updated to reflect this.
Discussed how data structures and the chosen heuristics could affect the implementation of A* if done poorly. One possible solution to this is to find an implementation of A* that is assumed to be efficient and use it for comparisons.
Began a sequential implementation of A* for a 2D map during the week, aim is to complete this for Friday 11th October and then continue work on it to lead to pathfinding over a dynamic 3D map.
Look into papers about parallel AI and continue with writing up lit review.
Discussed how data structures and the chosen heuristics could affect the implementation of A* if done poorly. One possible solution to this is to find an implementation of A* that is assumed to be efficient and use it for comparisons.
Began a sequential implementation of A* for a 2D map during the week, aim is to complete this for Friday 11th October and then continue work on it to lead to pathfinding over a dynamic 3D map.
Look into papers about parallel AI and continue with writing up lit review.
Friday, 27 September 2013
Gantt Chart
Gantt Chart showing the timeline for the project.
 |
| Click to enlarge |
Break Down
- Task 1 - Literature Review 01/10/13 - 05/11/13 (5 Weeks)
- Task 2 - Technical Review 01/10/13 - 05/11/13 (5 Weeks)
- Task 3 - Design 01/10/13 - 05/11/13 (5 Weeks)
- Task 4 - Implementation 01/10/13 - 14/01/14 (15 Weeks)
- Task 5 - Experiments and Testing 14/01/14 - 24/02/14 (6 Weeks)
- Task 6 - Analysis 14/01/14 - 24/02/14(6 Weeks)
- Task 7 - Write Up 01/10/14 - 07/04/14(28 Weeks)
- Task 8 - Make Poster 07/04/14 - 14/04/14(1 Week)
Impact on Rendering
Offloading AI onto the GPU may have an effect on rendering if too much of the resource is taken up by the pathfinding.
May need to be aware of and test this during the testing and evaluation stage of the project. possibly create a graph showing how much time is taken up by rendering vs pathfinding.
May need to be aware of and test this during the testing and evaluation stage of the project. possibly create a graph showing how much time is taken up by rendering vs pathfinding.
Meetings: Friday 27th September 2013
Looked over changes made to the IPO and agreed it was ready to be handed in. Submitted it to the school of computing office at 13:30.
Discussed impact that offloading AI onto the GPU may have an effect on rendering if too much of the resource is taken up by the pathfinding. May need to be aware of and test this during the testing and evaluation stage of the project. possibly create a graph showing how much time is taken up by rendering vs pathfinding.
create gantt chart of project plan for next Friday.
Look into implementing terrain, doesn't need to be complicated, don't actually need to render anything at this stage just need to be able to access the data correctly on the GPU with minimal passing of data between the CPU and GPU as this will cause a major slowdown and greatly effect performance. Look into getting interoperability working and storing the data in VBO's etc.
Keep reading papers for the lit and tech review.
Start draft chapters for the week 9 review and keep a log of any technical work done.
Discussed impact that offloading AI onto the GPU may have an effect on rendering if too much of the resource is taken up by the pathfinding. May need to be aware of and test this during the testing and evaluation stage of the project. possibly create a graph showing how much time is taken up by rendering vs pathfinding.
create gantt chart of project plan for next Friday.
Look into implementing terrain, doesn't need to be complicated, don't actually need to render anything at this stage just need to be able to access the data correctly on the GPU with minimal passing of data between the CPU and GPU as this will cause a major slowdown and greatly effect performance. Look into getting interoperability working and storing the data in VBO's etc.
Keep reading papers for the lit and tech review.
Start draft chapters for the week 9 review and keep a log of any technical work done.
Monday, 23 September 2013
Initial Project Overview
Title of Project: Comparison of Pathfinding Algorithms using the GPGPU
Overview of Project Content and Milestones
The aim of the project is to implement, test and evaluate a piece of software which compares multiple pathfinding algorithms that will be run in parallel using the GPGPU. The algorithms will be compared against CPU based implementations of themselves and against each other in a range of different pathfinding scenarios.
For the project to be successful the following aspects must be implemented. One traditional path finding algorithm implemented on both the CPU and GPGPU. One other pathfinding algorithm implemented on the CPU and GPGPU, Test both algorithms in a range of different scenarios from simple flat surfaces with few obstacles to varying terrain with a wide range of static and moving obstacles, the accompanying report and documentation.
The Main Deliverable(s):
Report showing an understanding of the project and an analysis of the data gathered comparing the chosen algorithms. To hopefully show that making use of the GPGPU for computation is a feasible option for path finding algorithms. The accompanying software containing parallel and sequential implementations of multiple pathfinding algorithms.
The Target Audience for the Deliverable(s):
Game Developers, AI researchers, parallel computing researchers, GPU manufactures.
The Work to be Undertaken:
Investigate current projects and literature which have similar goals to this and gain an understanding of their findings and what limitations and problems they faced, also to identify suitable metrics to compare the algorithms against.
Implement the chosen algorithms both on the CPU and GPGPU and test the differences in performance between the algorithms and their sequential and parallel implementations. Evaluate the data gathered to provide an understanding of the benefits/limitations of parallel pathfinding algorithms. Document the findings and the software to be included in the accompanying analysis and report.
Additional Information / Knowledge Required:
To complete the project and achieve the main goals, an understanding of programming for the GPGPU will be required. Knowledge of artificial intelligence and the different pathfinding algorithms will also be necessary.
Information Sources that Provide a Context for the Project:
Information about GPGPU programming
Khronos Group(OpenCL) - http://www.khronos.org/opencl/
Cuda by Example written by Jason Sanders and Edward Kandrot
Heterogeneous Computing with OpenCL written by Benedict R. Gaster, Lee Howes, David R. Kaeli, Perhaad Mistry and Dana Schaa.
Information about AI and Pathfinding
Artificial Intelligence For Games written by Ian Millington and John Funge.
AI Game Dev - http://aigamedev.com
The Importance of the Project:
A.I algorithms are one of the last parts of a typical game engine to be exploited by the GPU. By researching into this area and determining if it is possible and worthwhile to make use of these techniques could benefit game developers by allowing better and more efficient AI in games which will create a better experience for the player specifically in the mobile section where costly A.I can be a problem due to constraints on processing power and memory.
The Key Challenge(s) to be Overcome:
The biggest difficulty may be implementing the algorithms so they run on the GPGPU. There are limited resources on parallel implementations of traditional pathfinding algorithms and implementing traditional sequential algorithms in an efficient parallel way may be a difficult challenge to overcome.
Project Plan
1. Literature Review
- Pathfinding algorithms in general
- A*
- Ant Colony
- Diffusion
- Lazy theta *
- Parallel versions of pathfinding algorithms
- Pathfinding algorithms in different scenarios
- GPGPU programming
- Difference between CPU/GPU
- Advantages/Disadvantages
- Environments/Scenarios
- Look at environments from a game perspective
- Terrain
- Enemies
- Moving Obstacles
- Metrics for comparing algorithms
- sequential vs parallel
- quality of pathfinding algorithm
2. Technical Review
- Cuda
- OpenCL
- Game Engines
- My Own
- Irrlicht
- Rendering Engines
- Terrain
- What gives most control over meshes and least effect on performance.
- Physics
- Bullet
- Havok
- Is physics needed?
3. Design
- Algorithms
- pseudo code (sequential)
- pseudo code (parallel)
- scenarios
- different environments
- range of obstacles
- distance
- metrics
- what will be used?
- why are the useful?
4. Implementation
- Implement engine
- Terrain
- physics(if needed)
- cuda support
- implement algorithms
- sequential version of alg #1
- parallel version of alg #1
- sequential version of alg #2
- parallel version of alg #2
5. Experiments and Testing
- Test all implementations of the algorithms in all the identified scenerarios and gather the specificed metrics for each algorithm.
6. Analysis
- graph and compare results from experiments
- draw conculsions about the implementations of the algorithms
7. Write Up
- Write up and complete report.
Meetings: Friday 20th September 2013
Overview of our meeting on Friday 20th September.
Went over first draft of initial project overview and discussed what changes needed to be made before handing in on Friday 27th September.
Discussed what work needs to be completed for the following week.
Next Steps
Went over first draft of initial project overview and discussed what changes needed to be made before handing in on Friday 27th September.
Discussed what work needs to be completed for the following week.
Next Steps
- Create wiki for the project.
- Create plan for the project.
Subscribe to:
Comments (Atom)